
For digital advertisers, deterministic and probabilistic usually relate to data models, and not the kind that are on Project Runway. These data models can be used to drive methods for tracking a person – across devices, across networks, across channels, over time, online & offline.
Deterministic certainty vs. probabilistic guessing
Lots of people think in a binary, black & white manner. Life is sometimes that way, but more often not. You are either dead or alive – but, between birth & death you are closer to one state than the other on a sliding scale. The same is true of the distance between a guess & certainty when tracking a person.
Across devices, on different digital properties, over time, pure deterministic tracking is not realistic. Regardless, the more certain I am (the less that I guess), the better. That’s where the deterministic nature of social media pays off – when the person using the platform is always known (because you have to be logged into your account to use social media). The challenge is tracking the person as they move away from social media platforms to other digital properties.
Keep social media in the know with tag management
No one reports an ad platform’s performance better than that platform. The ad platform obviously knows when its ad is presented or clicked. If I use a tag management solution to inform that ad platform when a user converts on an external digital property – that ad platform can tie the conversion back to the ad view or click with relative determinism (notwithstanding some ITP uncertainty; and don’t forget GDPR compliance).
Perfect isn’t the only enemy of good

In some rare situations we have perfect information in making decisions. Consider the game of chess. There are specific rules that must be followed. Both players know the rules, can see all the pieces all the time – and can also see the moves of their opponent as they happen. Even with chess where we have perfect information, the game is still very difficult.
There is only so much information we can process – so even with perfect information, we end up having to do some guessing. We make simplifications, or rules of thumb, to help us make decisions when a deterministic solution to a problem isn’t possible.
This kind of thinking should be at play in digital advertising, where we certainly do not have perfect information. We should be OK with some guessing. The challenge is that many vendors portray their digital advertising targeting & performance reporting as if it is deterministic when in reality there is heavy probabilistic guessing driving their solution. Google Ads store visits conversions are based on probabilistic data modelling. Google notes this is modeled data in their About store visit conversions help content, but it is not obvious – and the vast majority of advertisers do not realize this conversion is a guess. It is probably a very good guess, but still a guess – not “deterministic certainty”.
We certainly don’t want to only advertise when we have perfect deterministic information about our targets (i.e., don’t let perfect be the enemy of good). But, we also don’t want to over dilute our targeting, or performance analysis, with loose probabilistic guessing (i.e., sloppy guessing is also the only enemy of good).
Targeting first, then messaging

A crappy ad put in front of the right target will perform way better than a perfect ad put in front of the wrong target. That’s not a license to be OK with stinky ads – it is a call to make targeting your first priority. First figure out who you want to get your ad in front of (with consideration for how & when), and then figure out the message you want to put in front of them.
As noted, over diluting targeting can bankrupt the return on your ad spend. Sadly, some ad platforms make it very, very easy to over dilute campaign targeting. They have a financial incentive to suggest targeting that gets ads in front of as many users as possible, increasing their chances of generating as much ad revenue & profits as possible. Google Ads gives you controls to combat over diluted targeting, but they make also make it plenty easy to do – here’s a couple of examples:
- Similar audiences are only as good as the seed data used to create them (e.g., all visitors to your website vs. visitors that converted). And, Google has an incentive to make similar audiences lists bigger so they get ads in front of more users when used for targeting. You have zero control over how much they guess when defining similar audiences (i.e., what attributes are required to include a user in a similar audience). Facebook gives you some control with the “audience size” option, with 1 to 10% options – where 1% is produces a smaller list, but more closely matched “lookalikes”.
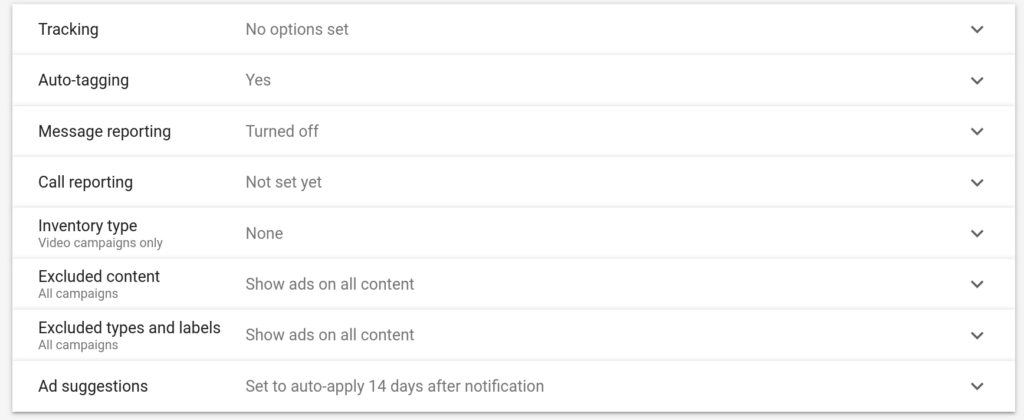
- Google Ads account settings, by default, include the broadest available options for expanded inventory, with no exclusions engaged (ads will show relative to raunchy content by default). And, most disturbingly – “ad suggestions” are set to automatically be executed in 14 days, by default. We challenge you to try to find where you can edit these settings in Google Ads (they do a great job of burying them). So, if this option is engaged, and you don’t monitor these suggestions to opt out of what you don’t agree with – they get automatically applied. These suggestions can include adjustments that “turn up the volume” on probabilistic guessing if your ads are not getting enough impressions or clicks to consume your budget.
The 80-20 Pareto principle
The Pareto principle says roughly 80% of the effects come from 20% of the causes. We can apply this principle to digital advertising:
- 80% of your converted users come from 20% of the users you target.
- 80% of your revenue / profits come from 20% of your converted users.
If we can manage to get our ads in front of those 20% of converted users that will generate the lion’s share of our profits, we are doing pretty darn good. How do we do this? We pause our worst performing campaigns, increase budget on our best ones, and make some effort to consider in our strategy what our competition is doing. If we are disciplined, we can commit only 20% as much resources, and 80% of the time we’ll be getting our ads in front of the best possible users (80% of the time our results will be what we’d get if we had perfect deterministic information, and the ability or tools to process it optimally).
The key is predicting who is most likely to buy, and getting ads in front of those users. In other words, targeting is critical – as is a consistent process for measuring how well you targeted, and making adjustments to improve.
It’s not just how well you guess, it’s how well you guess relative to the competition
Sometimes winning isn’t based on the accuracy of your predictions, but rather how good they are relative to the competition. So pick the right battles. Strength of competition matters. You can be profitable being pretty good where competition makes bad decisions. Where competition has the basics right, it is much harder to be very good. In that case, don’t fool yourself into thinking you have an edge. You might just want to stay at fringes, where competition is low and margins are high.
If you can’t spot 1 or 2 bad players in the game you are playing, you probably should not be playing.
Much of the content on this page was inspired directly or indirectly by this awesome book by Nate Silver.